不看K线!对冲基金的量化分析师到底看什么数据?
自从AlphaMind AI上线,很多朋友总问我们到底是怎么生成那么多可以不断盈利的交易信号。其实答案并不神秘,不是“灵感”或者“运气”,而是一个来自对冲基金量化的底层逻辑与AI的结合。所以今天的文章,就讲讲到底什么数据可能被我们的AI参考。
谈到交易员,很多人脑中浮现的通常是闪烁的K线图、各种各样的技术指标、几张组合在一起的显示器。但在真正的量化机构眼里,这些更像是小孩的玩具。
如果你走进像Two Sigma和Citadel的办公室,他们的屏幕上出现的东西,可能完全超出你的想象:停车场的卫星俯瞰图、集装箱船的实时位置、上百万张信用卡账单的匿名消费记录、甚至GitHub上某家SaaS公司代码提交的频率。
这就是另类数据的世界。对顶级量化基金来说,公开的市场价格与财报数据只占它们每天接触的信息的不到 5%。剩下的 95%,来自各种“不好拿、不好懂”的非结构化数据:统计模型、卫星图像、交易行为、物流链、文本情绪、网页爬虫、天气、物联网……几乎你想得到和想不到的,都能成为Quant武器库的一部分。
为什么要这样做?因为传统数据已经被挖空了,其实也就是有效市场假说。大家都基于同样的财报、价格、成交量等等建模型,任何能带来超额收益的Alpha早都失效了。一名顶级量化分析师的任务,就是在“别人还没看到信息前”,就找到能反映经济活动的更提前、更新鲜的指标。
过去十年,这种方法只存在于行业最顶级的基金里。但随着AI的能力爆发,一部分工具开始被“平民化”。例如我们的产品AlphaMind AI,本质就是把这一套逻辑与人工智能模型结合,做成普通交易者也能使用的量化模型信号与市场分析系统。
不过,顶级量化的规模与壁垒依旧存在,但市场的透明度正在被技术逐步改变。
为什么量化必须要另类数据?
金融市场是一个“几乎不可预测且极度复杂”的系统。K线图反映的是过去的走势,价格则是一个结果变量,并非未来价格变化的原因。量化真正寻找的是能领先价格变动的“因”。
传统的量价因子(基于价格走势及成交量),在市场越来越透明的今天,已几乎不可能带来持续有效的 Alpha,如果谁跟你说他依靠分析k线图长期盈利,大概率是忽悠。类似的,许多因子被反复利用后,收益率迅速衰减。
另类数据的核心价值来自两个维度:
一是“稀缺”。别人没有的数据,你有。
二是“复杂”。别人看不懂的数据,你能清洗成结构化信息。
在这种逻辑下,停车场卫星图、供应链物流速度、员工在 Glassdoor 上的情绪变化,甚至 CEO 私人飞机的航线,都能在财报之前数周甚至数月反映真实经营情况。
量化的核心目标,就是找到这些领先指标。
贝叶斯模型、卡尔曼滤波、图网络、时间序列模型等等,一些微弱但真实的因果关系,经过无数次融合,清洗,也许就能变成强信号。
如果你使用AlphaMind的短线分析功能,你能看到类似的理念被“简化”后应用于用户:AI会结合统计模型,宏观数据、资金流、技术周期、新闻情绪等信息自动生成趋势方向、风险预警以及择时信号。这实际上就是把“另类数据”做成普通用户能理解的形态。
Two Sigma每年会审核超过 10,000 套另类数据集,但最终能投产的不到 1%。Citadel则更强调通过自身做市业务构建的高频“微观结构数据”,一种散户永远无法获得的数据优势。
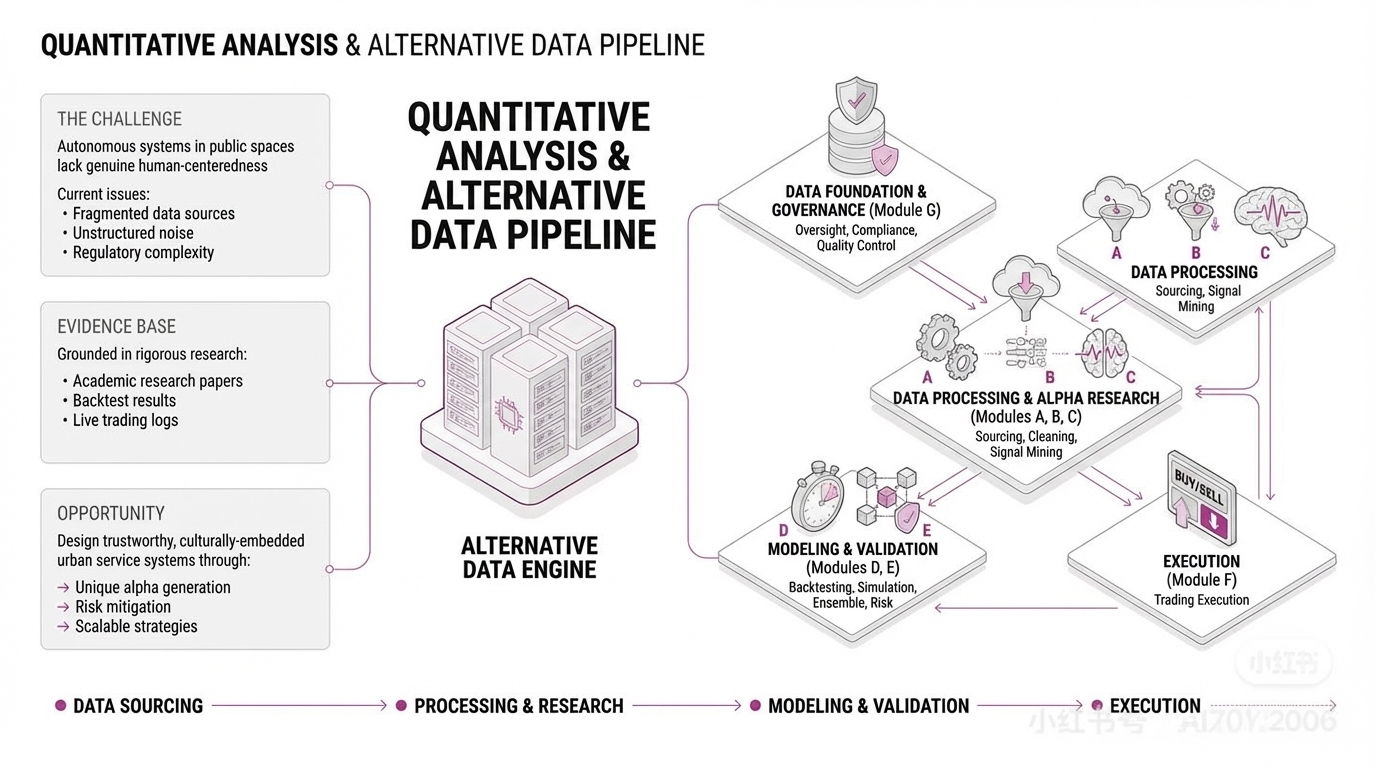
顶级量化如何从这些海量数据中找到真正能带来收益的信号?整个流程可以分成七大模块。
模块 A:数据搜寻(Data Sourcing)
Two Sigma 内部有一个 Alpha Capture / Data Sourcing Group,专门负责从全世界搜集一切可能的数据源。他们会去行业会议拜访供应商、与卫星公司签合作、自己建爬虫、与SaaS平台交换数据、购买全球统计数据、分析GitHub,reddit活跃度、甚至利用AI自动搜索可商业化数据。
对于每一套数据,量化基金会从六个维度评判价值:独特性、及时性、覆盖度、频率、噪音比、合规性。
真正能进入最终策略的,少之又少。
模块 B:数据清洗(Data Cleaning × Engineering)
另类数据最难的不是什么时候买,而是清洗”。
量化机构可能会进行自动化异常检测、网页结构变化监测、机器人与假用户识别、异常跳变过滤等。之后要进行对齐:把不同来源的数据统一到同一个时间、公司代码、地域、SKU等维度。
缺失值处理更是关键。例如Two Sigma会使用序列模型 + 机器学习组合方式,确保时间序列连续性。
在AlphaMind,我们踩过非常类似的坑——市场新闻噪音极高,金融文本有大量歧义,价格数据不同步……
因此,我们花费了大量时间训练AI 自动降噪 + 自动结构化的能力。
模块 C:信号挖掘(Alpha Research)
这里的研究已经不是“做因子”,而是一整套科学化流程:
举个例子:企业招聘人数增加 → 研发投入增加 → 利润增长
停车场流量 → 销售额预测
夜间灯光强度 → GDP 增速预测
船舶路径变化 → 大宗商品进口与价格预测
随后是机器学习模型构建:GBDT、随机森林、XGBoost、GNN、LSTM、Transformer 等等。
AlphaMind的AI预测方向和信号判断,就是基于类似的“多因子融合”理念,但使用的是公开数据+生成式 AI 解释能力,让散户也能看懂。
模块 D:信号验证(Backtesting × Simulation)
任何数据都无法直接拿来交易。机构通常会有三层验证:
长周期历史回测(跨市场、10 年以上、模拟成本)
合成数据测试(扰动、噪音、删除部分数据)
生产环境模拟(Paper Trading)
Citadel的模拟系统甚至可以完整复刻真实交易对手行为及市场冲击。
模块 E:模型集成(Ensemble × Risk)
通过验证的信号,还要能与基金内部数千个其他信号共存,不互相打架。
例如分层模型、PCA、贝叶斯平均等方式的融合。
风控则会考虑容量、流动性冲击、相关性风险、仓位暴露等等。
模块 F:交易执行(Execution)
对于Quant来说,执行(交易)成本甚至可以说是任何策略中最重要的部分。
智能下单系统、暗池路由、延迟优化、市场冲击建模、高速光纤/微波网络、Tick 级数据反馈……任何量化机构都会想尽办法提升速度,在市场反应之前下单。
模块 G:数据治理(Data Governance)
另类数据如果不治理,会带来法律与模型崩溃风险。机构会给每个数据集分配ID,记录lineage,定期审核,确保任何隐私数据的匿名化。
另类数据的案例
卫星遥感。通过停车场汽车数量预测沃尔玛季度营收,利用影像阴影推算原油罐液位。
供应链与航运数据。利用 AIS 信号估算全球石油运输量变化。
信用卡与电子收据。预测 Netflix、星巴克、Lululemon 等 B2C 企业实时销售。
企业私有飞机飞行记录。CEO 的私人飞机偏向某城市,可能意味着并购谈判。
Glassdoor 文本情绪。员工连续几个月给差评,是管理层出问题的预警。
Reddit / Twitter 情绪分析。量化公司构建“散户情绪指标”,预测空头挤压风险。
微观结构数据。Citadel 用订单簿、成交簇、流动性挤兑等构建高频信号。
这些数据让顶级基金在财报公布前几个月,就对公司状况心里有数。
为什么散户做不了?
既然数据可以买,为什么散户不行?
第一,数据清洗极其困难。
卫星图像是毛坯图,信用卡数据充满偏差,文本数据噪音巨大……顶级基金可能有 50% 的人力投入在数据工程,而不是建模型。
第二,昂贵的成本。
一套高质量的信用卡或卫星数据,可能一年几十万美元甚至上百万。
第三,回测陷阱。
数据存在“未来函数”。比如你以为拿到了过去某天的卫星图,但实际上图像因为处理与传输有所延迟,导致你在历史时间点上根本拿不到这些信息。顶级基金用Point-in-Time数据库避免这种错觉,散户根本搭建不起。
从K线图到卫星图,量化的本质没变:
在不确定中寻找确定性。
但今天的顶级量化机构,越来越像科技公司——它们不是在“交易”,而是在构建一个全球级的信息压缩系统,用数据重新理解世界。
随着生成式AI的发展,下一个Alpha策略可能藏在你发的朋友圈、手机支付记录、或者一艘货船的航线偏移里。
对于想进入这个行业的人,不要单纯只迷信数学公式
计算机视觉
自然语言处理
分布式数据处理
模型工程
生成式 AI
这也是 AlphaMind 正在大量投入的方向,
我们希望做的,就是把这种能力,从顶级对冲基金,带给更多普通投资者。